Passo 1
Brief machine-ready
L'AI traduce esigenze non strutturate in una richiesta di progetto tecnica e machine-ready.
Utilizziamo i cookie per migliorare la tua esperienza e analizzare il traffico del sito. Puoi accettare tutti i cookie o solo quelli essenziali.
Smetti di scorrere liste statiche. Dì a Bilarna le tue esigenze specifiche. La nostra AI traduce le tue parole in una richiesta strutturata e machine-ready e la inoltra subito a esperti Gestione dei Dati di Ricerca verificati per preventivi accurati.
L'AI traduce esigenze non strutturate in una richiesta di progetto tecnica e machine-ready.
Confronta i fornitori usando AI Trust Score verificati e dati strutturati sulle capacità.
Salta il contatto a freddo. Richiedi preventivi, prenota demo e negozia direttamente in chat.
Filtra i risultati per vincoli specifici, limiti di budget e requisiti di integrazione.
Elimina il rischio con il nostro controllo di sicurezza AI in 57 punti su ogni fornitore.
Aziende verificate con cui puoi parlare direttamente

Fully leverage the experimental data you collect in the lab with Labric's platform. Sync instruments, automate workflows, structure your data, and accelerate research on your terms.
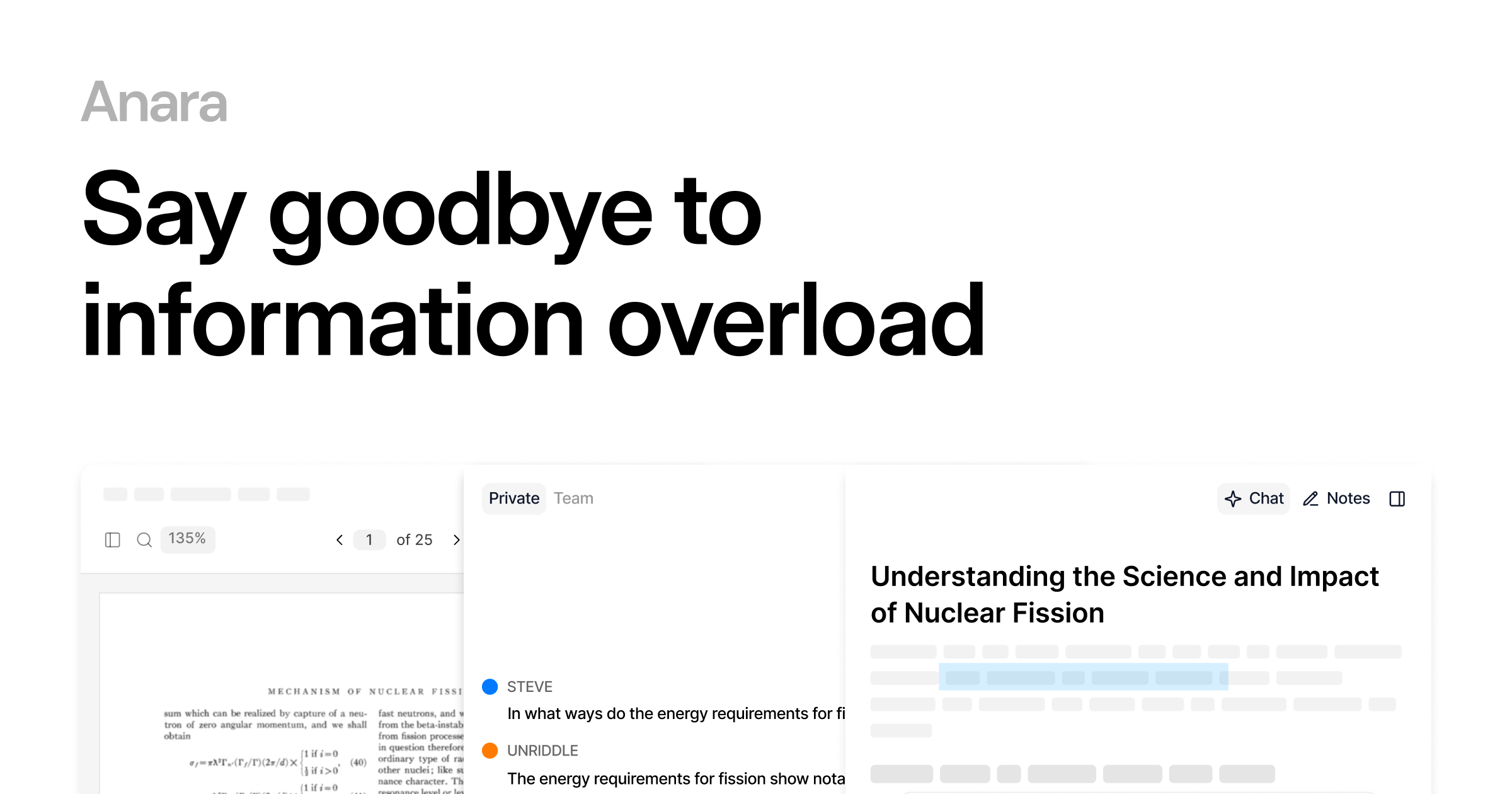
Automate your research workflows with Anara's AI. Build research library, verify sources, and collaborate with your team. Trusted by researchers worldwide.
Esegui un audit gratuito AEO + segnali per il tuo dominio.
AI Answer Engine Optimization (AEO)
Inserisci una sola volta. Converti l'intento dalle conversazioni AI dal vivo senza integrazioni pesanti.
La Gestione dei Dati di Ricerca è il processo sistematico di raccolta, organizzazione, archiviazione, preservazione e condivisione dei dati generati durante l'indagine scientifica e accademica. Implica l'implementazione di politiche, strumenti e infrastrutture per garantire l'integrità, la riproducibilità e l'accessibilità a lungo termine dei dati. Una gestione efficace trasforma i dati grezzi in un bene sicuro e riutilizzabile che accelera le scoperte e soddisfa i mandati di conformità dei finanziatori.
Stabilire un piano di gestione dei dati (PGD) dettagliato che delinei i metodi di raccolta, standard di metadati, soluzioni di archiviazione e controlli di accesso prima dell'inizio del progetto.
Utilizzare software specializzati e repository per l'acquisizione sicura, pulizia, annotazione, controllo delle versioni e trasformazione dei dataset di ricerca durante il loro intero ciclo di vita.
Archiviare i dataset finali in repository conformi ai principi FAIR, con identificatori persistenti e accesso controllato per consentire verifica, riutilizzo e futura collaborazione scientifica.
Garantisce la conformità ai requisiti di finanziamento di enti come il MIUR o il CNR, preservando i dati per la validazione accademica a lungo termine e studi interdisciplinari.
Mantiene la tracciabilità e l'integrità dei dati degli studi clinici, cruciali per le presentazioni normative ad agenzie come l'AIFA o l'EMA.
Gestisce grandi dataset sensibili ambientali o demografici, assicurando accesso sicuro, trasparenza pubblica e analisi che informano le politiche.
Protegge la proprietà intellettuale nei dataset genomici e proteomici, strutturando i dati per attrarre investimenti e facilitare collaborazioni di ricerca.
Standardizza i dati sperimentali di più laboratori per guidare l'innovazione, proteggere i segreti commerciali e supportare le domande di brevetto in settori competitivi.
Bilarna valuta ogni fornitore di Gestione dei Dati di Ricerca utilizzando un Punteggio di Affidabilità IA proprietario di 57 punti, analizzandone competenza tecnica, protocolli di sicurezza dei dati e certificazioni di conformità. Convalidiamo il loro portfolio di progetti, riferimenti clienti e storico di consegna per garantire che soddisfino i rigorosi standard della ricerca scientifica. Questo monitoraggio continuo assicura che ti connetti con esperti meticolosamente verificati sulla nostra piattaforma.
L'obiettivo principale è rendere i dati di ricerca Facilmente reperibili, Accessibili, Interoperabili e Riusabili (principi FAIR). Ciò migliora la riproducibilità scientifica, protegge l'integrità dei dati e massimizza il valore a lungo termine degli investimenti in ricerca, trasformando i dati in beni durevoli per future indagini.
I costi variano significativamente in base alla scala del progetto, alla complessità dei dati e al livello di sicurezza richiesto, da migliaia a centinaia di migliaia di euro all'anno. I fattori includono licenze software, costi di archiviazione cloud, personale specializzato e audit di conformità continui. Ottenere preventivi dettagliati da più fornitori è essenziale per una pianificazione di budget accurata.
Caratteristiche essenziali includono una robusta gestione dei metadati, controllo delle versioni, gestione delle autorizzazioni di accesso, tracce di audit e integrazione con strumenti di analisi. Le piattaforme leader offrono anche backup automatizzato, ripristino di emergenza, supporto per formati di dati su larga scala e conformità a standard specifici come DICOM in ambito sanitario.
Un Piano di Gestione dei Dati è un documento formale creato all'inizio di un progetto che dettaglia come i dati verranno gestiti durante e dopo il processo di ricerca. Specifica tipi di dati, formati, standard di metadati, procedure di archiviazione e backup, politiche di condivisione e piani per la preservazione e l'archiviazione a lungo termine.
L'implementazione iniziale per un gruppo di ricerca standard può richiedere da 3 a 6 mesi, coprendo pianificazione, configurazione del software e formazione del team. Le implementazioni istituzionali su larga scala con integrazione personalizzata possono richiedere da 12 a 18 mesi. La tempistica dipende fortemente dai sistemi legacy, dai requisiti di conformità e dalla prontezza al cambiamento dell'organizzazione.
Quando si seleziona un fornitore di gestione del rischio informatico, si dovrebbe cercare una suite completa di servizi che copra l'intero spettro delle sfide di cybersecurity. Un fornitore ideale offre soluzioni integrate che spaziano dalla sicurezza offensiva proattiva, come i test di penetrazione, alla risposta agli incidenti e forense digitale (DFIR) reattiva. Dovrebbero possedere un'esperienza comprovata e utilizzare tecnologie di prim'ordine per fornire questi servizi. Fondamentalmente, il fornitore deve dimostrare la capacità di sintetizzare le informazioni provenienti sia da impegni offensivi che difensivi per creare un ciclo di feedback continuo che rafforzi la postura di sicurezza complessiva. Questo approccio olistico garantisce che le vulnerabilità vengano identificate, gli attacchi vengano investigati e le difese vengano sistematicamente migliorate sulla base di intelligence del mondo reale, consentendovi di rimanere un passo avanti rispetto alle minacce in evoluzione.
Quando si sceglie un partner per soluzioni di AI e dati, si dovrebbe dare priorità a un'esperienza comprovata in tecnologie specifiche, un'esperienza settoriale rilevante e un forte impegno per la sicurezza e la conformità. Innanzitutto, valutate le loro capacità tecniche in aree chiave come i modelli linguistici di grandi dimensioni (LLM), le piattaforme di manutenzione predittiva, le soluzioni data-as-a-service e gli agenti di AI enterprise. Cercate partnership consolidate con i principali fornitori di tecnologia come Microsoft per Fabric e Azure AI, Snowflake per il cloud dati e n8n per l'automazione, in quanto indicano una validazione tecnica. In secondo luogo, valutate la loro esperienza nel vostro settore specifico, che si tratti della produzione per la manutenzione predittiva, dei servizi finanziari per strumenti di investimento più intelligenti o del marketing per l'AI di garanzia del marchio. Infine, assicuratevi che il partner rispetti severi standard di sicurezza dei dati, possieda certificazioni come la ISO 27001 e possa operare in ambienti cloud sovrani se richiesto per la residenza dei dati.
Quando si sceglie una società di gestione associativa (SGA), il criterio principale dovrebbe essere la loro comprovata esperienza ed esperienza nel vostro specifico settore industriale, come quello sanitario, tecnologico o manifatturiero. È essenziale valutare il loro portafoglio di servizi per assicurarsi che sia in linea con le vostre esigenze, coprendo aree critiche come la gestione finanziaria, la pianificazione degli eventi, i servizi ai soci e il supporto strategico alla governance. Valutare la loro capacità tecnologica è altrettanto vitale; una SGA competente dovrebbe utilizzare software moderni per il CRM, la reportistica finanziaria e la gestione degli eventi per garantire efficienza e trasparenza. Inoltre, esaminate il loro portafoglio clienti e richiedete referenze per verificare la loro reputazione in termini di affidabilità, servizio clienti eccezionale e un track record di successo nella gestione di associazioni di dimensioni e complessità simili alle vostre.
Quando si seleziona un software di gestione del flusso di lavoro, dare priorità a soluzioni che offrono un'automazione completa dei processi, robuste capacità di integrazione e un design user-friendly. Innanzitutto, assicurarsi che il software possa automatizzare flussi di lavoro di approvazione complessi e multi-dipartimentali per funzioni chiave come approvvigionamento, risorse umane e firma di documenti, con regole e condizioni personalizzabili. In secondo luogo, deve integrarsi perfettamente con i sistemi esistenti, come piattaforme CRM, ERP o di posta elettronica, per creare un ecosistema digitale unificato. In terzo luogo, cercare interfacce utente intuitive e accesso mobile per facilitare l'adozione da parte di tutti i dipendenti, compresi i team remoti. Inoltre, considerare soluzioni con forti funzionalità di conformità come tracce di audit e firme elettroniche per la validità legale. Infine, valutare la comprovata esperienza del fornitore nel vostro settore e il suo impegno per il supporto a lungo termine e l'evoluzione del sistema per garantire che la soluzione si adatti alle esigenze aziendali.
Quando si assume un'agenzia di gestione Google Ads, dare priorità a competenze comprovate, trasparenza e una storia di consegna del ROI. Cercate agenzie con esperienza nella gestione di spese pubblicitarie sostanziali, poiché ciò indica competenza nella gestione di campagne complesse e budget elevati. Assicuratevi che forniscano casi di studio dettagliati o testimonianze dei clienti che dimostrino risultati misurabili, come conversioni aumentate o costi per acquisizione ridotti. La trasparenza nei prezzi e nella reportistica è cruciale; evitate agenzie con commissioni nascoste e insistete su aggiornamenti regolari delle prestazioni. Inoltre, verificate il loro utilizzo di strumenti avanzati e automazione per l'ottimizzazione, l'adattamento strategico ai cambiamenti del mercato e l'allineamento delle campagne ai vostri specifici obiettivi aziendali per il successo a lungo termine.
Quando si sceglie un servizio di gestione dei social media, cercare un fornitore che sviluppi e implementi una strategia unica e personalizzata allineata ai propri obiettivi aziendali specifici. Il servizio dovrebbe offrire una gestione completa, inclusa la creazione di contenuti, la pianificazione dei post, l'engagement della comunità e l'analisi delle prestazioni. Un fattore chiave è la loro capacità di aumentare l'interazione e l'engagement del pubblico, che è il metodo principale per far crescere la visibilità di prodotti o servizi. Il fornitore dovrebbe dimostrare esperienza nello sviluppo di una voce di marca coerente su diverse piattaforme. Inoltre, valutate le loro capacità di reporting per assicurarvi che forniscano chiare informazioni sull'efficacia della campagna e sul ritorno sull'investimento, permettendo un'ottimizzazione continua della strategia.
Quando si sceglie un'agenzia di marketing digitale basata sui dati, si dovrebbe dare priorità a una metodologia collaudata per raccogliere, analizzare e agire sui dati di performance della campagna per guidare le decisioni. Cerca pratiche di reporting trasparenti che colleghino chiaramente gli sforzi a specifici risultati aziendali come tassi di conversione aumentati, crescita del traffico organico o miglioramenti nel posizionamento delle parole chiave. L'agenzia dovrebbe dimostrare competenza su più canali (SEO, PPC, social media) e avere case study che mostrino risultati misurabili come aumenti percentuali nelle metriche chiave. Valuta il loro impegno in un ciclo 'testa, misura, ottimizza', il loro uso di strumenti analitici avanzati e la loro capacità di fornire un'analisi competitiva dettagliata e gratuita per valutare la tua posizione. In definitiva, scegli un'agenzia che tratta il marketing come una scienza, non solo come un esercizio creativo.
Quando si sceglie un'agenzia di visualizzazione dati, dare priorità a un portfolio collaudato con case study che dimostrino chiari risultati aziendali, come un maggiore coinvolgimento degli utenti o un miglioramento del processo decisionale. Cercate competenze tecniche sia negli strumenti di progettazione (come Figma o Adobe Creative Suite) che nelle tecnologie dei dati (come D3.js, Tableau o Power BI). L'agenzia dovrebbe avere un processo rigoroso per comprendere il contesto dei vostri dati, garantendo accuratezza e chiarezza narrativa nelle visualizzazioni finali. Valutate il loro approccio collaborativo; dovrebbero lavorare a stretto contatto con il vostro team per comprendere sia le fonti dei dati che gli obiettivi strategici. Infine, valutate la loro capacità di creare output che non siano solo visivamente accattivanti, ma anche accessibili, intuitivi per gli utenti finali e in grado di essere integrati nei vostri ecosistemi digitali esistenti, come siti web o dashboard interni.
Un'azienda dovrebbe cercare una combinazione di comprovata esperienza, processi trasparenti e una metodologia orientata ai risultati quando sceglie un'agenzia di gestione SEO o PPC. I criteri chiave includono esperienza specifica del settore e un portfolio che dimostri il successo con aziende simili. L'agenzia dovrebbe impiegare professionisti certificati, come quelli con certificazioni Google Ads e Analytics, indicando una conoscenza formale della piattaforma. La trasparenza è fondamentale; l'agenzia deve fornire report chiari ed essere facilmente accessibile per consultazioni, offrendo insight sulle prestazioni delle campagne e sugli aggiustamenti. Una focalizzazione sulle vendite e sul ROI, piuttosto che solo sulle metriche del traffico, distingue un partner strategico da un fornitore di servizi di base. Infine, cercate un'agenzia che utilizzi strumenti analitici avanzati per effettuare ottimizzazioni basate sui dati quotidianamente, settimanalmente e trimestralmente, e che offra una strategia completa, potenzialmente integrando sia SEO che PPC, personalizzata su obiettivi aziendali specifici, pubblico di riferimento e panorama competitivo.
Quando si seleziona un servizio di ingegneria del software, cerca recensioni dei clienti che menzionano la consegna costante di lavoro di alta qualità, comunicazione efficace e gestione progetti affidabile. Concentrati su recensioni che lodano l'integrità incrollabile, l'attenzione meticolosa ai dettagli e la capacità di superare le aspettative, poiché ciò indica un partner affidabile. Esempi specifici da cercare includono lanci di app di successo su piattaforme principali, feedback positivi sull'esperienza utente e contributi a traguardi aziendali come il riconoscimento Forbes. Recensioni che notano partnership a lungo termine, reattività alle domande e adattabilità alle esigenze del cliente dimostrano impegno e capacità. Questi elementi assicurano che il fornitore di servizi possa gestire progetti complessi e favorire collaborazioni produttive per un successo sostenuto.