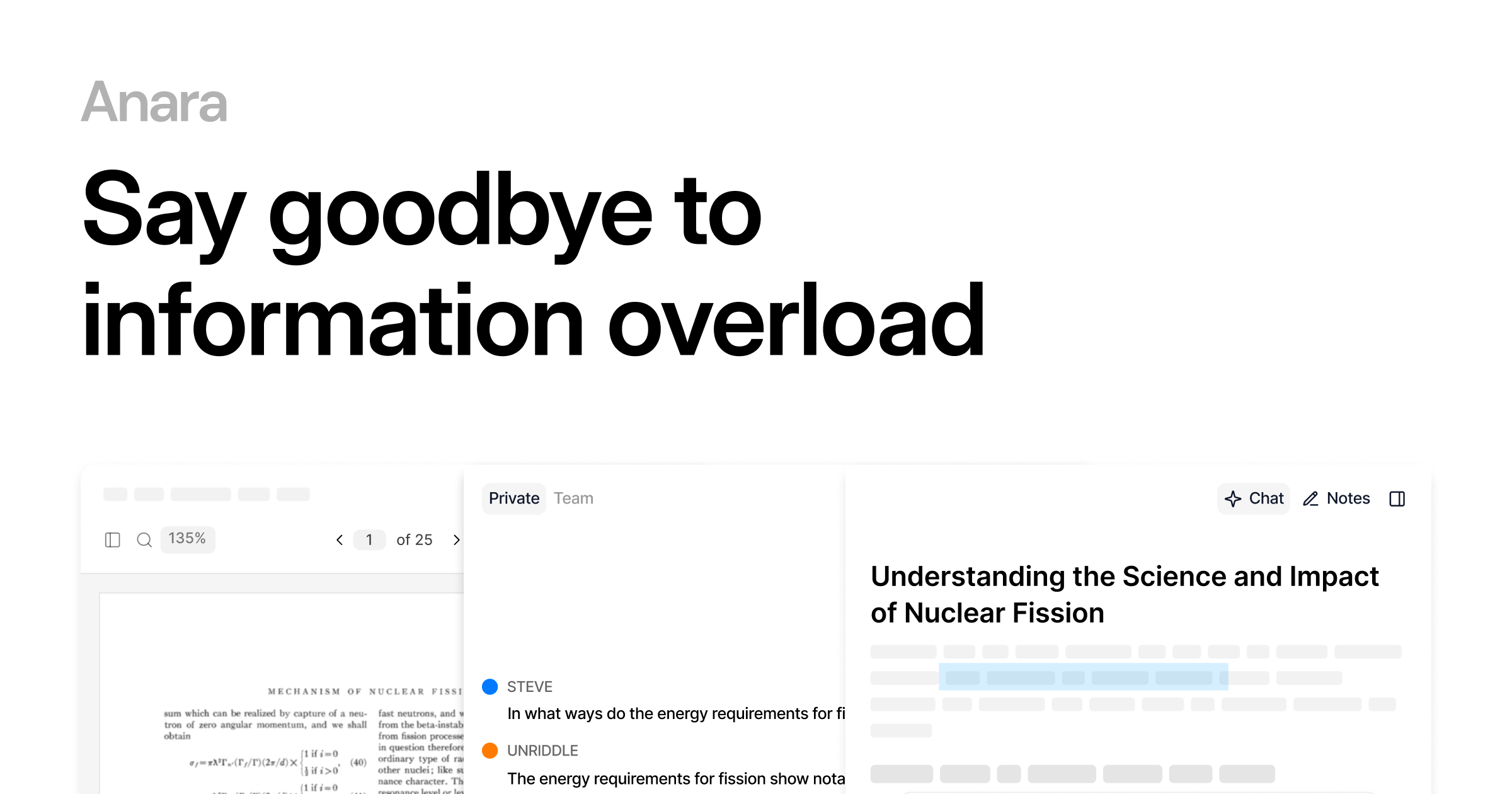
Step 1
Comparison Shortlist
Descrivi una volta → shortlist immediata di fornitori Gestione Dati di Ricerca Ia pertinenti.
Utilizziamo i cookie per migliorare la tua esperienza e analizzare il traffico del sito. Puoi accettare tutti i cookie o solo quelli essenziali.
Descrivi una volta → shortlist immediata di fornitori Gestione Dati di Ricerca pertinenti.
Descrivi una volta → shortlist immediata di fornitori Gestione Dati di Ricerca Ia pertinenti.
Chiarezza decisionale tramite profili verificati e fatti strutturati.
Prenota demo, preventivi e chiamate direttamente nella conversazione.
Affina l’abbinamento con domande di follow‑up e fattori distintivi.
Il livello di fiducia riduce tempi e rischi di valutazione.
Aziende verificate con cui puoi parlare direttamente


Esegui un audit gratuito AEO + segnali per il tuo dominio.
AI Answer Engine Optimization (AEO)
List once. Convert intent from live AI conversations without heavy integration.
La Gestione dei Dati di Ricerca (GDR) è la pratica di organizzare, conservare, proteggere e condividere i dati durante l'intero ciclo di vita di un progetto scientifico. Comprende tecnologie come i notebook elettronici di laboratorio (ELN), i repository dati, gli standard di metadati e i sistemi di controllo degli accessi, ed è essenziale in settori quali le scienze della vita, le scienze sociali, la fisica e l'ingegneria. I suoi benefici principali sono garantire l'integrità e la riproducibilità dei dati, rispettare i mandati di finanziatori come il MIUR o le linee guida dell'AGID, favorire la collaborazione scientifica e preservare il valore a lungo termine degli investimenti in ricerca.
I fornitori di soluzioni di Gestione dei Dati di Ricerca includono software house specializzate come Dataverse, DSpace o Open Science Framework; grandi provider cloud con servizi per la ricerca; e società di consulenza che offrono servizi di implementazione e supporto. Molti di questi fornitori possiedono certificazioni di sicurezza informatica e sviluppano soluzioni allineate ai quadri normativi nazionali ed europei, come il Piano Nazionale per la Scienza Aperta o i principi FAIR per i dati della ricerca.
La Gestione dei Dati di Ricerca funziona attraverso un flusso di lavoro definito, dalla pianificazione e documentazione dei dati al loro deposito sicuro in repository cloud o on-premise, fino alla condivisione controllata o all'archiviazione a lungo termine. I modelli di pricing più comuni sono gli abbonamenti SaaS, scalabili in base allo spazio di archiviazione o al numero di utenti, con costi che vanno da piani individuali a contratti istituzionali complessi. L'implementazione può richiedere da poche settimane per strumenti cloud a diversi mesi per infrastrutture su misura. I fornitori generalmente offrono percorsi digitali di acquisto, come richieste di preventivo online, demo della piattaforma e prove gratuite che consentono di caricare dataset campione per valutarne le funzionalità.
Gestione dei Dati di Ricerca — ottimizza raccolta, archiviazione e condivisione per l'integrità scientifica. Scopri e confronta fornitori verificati con approfondimenti basati su IA su Bilarna.
View Gestione dei Dati di Ricerca providersServizi di gestione dati di ricerca efficienti garantiscono archiviazione sicura, documentazione corretta e condivisione facile dei dati di ricerca.
View Servizi di Dati di Ricerca providersSoluzioni di archiviazione e analisi dei dati integrano gestione e analytics per generare insight. Confronta fornitori B2B verificati sul mercato di Bilarna con il Punteggio di Affidabilità AI a 57 punti.
View Soluzioni Archiviazione e Analisi Dati providersCombinare la tecnologia AI con la gestione umana dei dati sfrutta i punti di forza di entrambi per migliorare l'accuratezza e l'affidabilità dei dati. L'AI può elaborare grandi volumi di dati rapidamente e identificare modelli o cambiamenti in tempo reale, mentre gli esperti umani forniscono una revisione dettagliata e un controllo di qualità per garantire completezza e correttezza. Questo approccio ibrido produce dati più affidabili, riduce gli errori e mantiene standard elevati che i sistemi puramente automatizzati potrebbero trascurare. Inoltre, consente una gestione dei dati scalabile ed efficiente che bilancia la velocità tecnologica con il giudizio umano, supportando infine decisioni aziendali migliori e relazioni con i clienti migliorate.
Le piattaforme dati basate sull’IA per la ricerca scientifica offrono diverse caratteristiche chiave che migliorano la gestione e l’accessibilità dei dati. Queste includono il tagging avanzato dei metadati e l’indicizzazione, che organizzano dati strutturati e non strutturati per migliorare la precisione delle ricerche. Le capacità di ricerca potenziate dall’IA consentono ai ricercatori di individuare rapidamente i dataset rilevanti, riducendo significativamente i tempi di ricerca. Il tracciamento automatico delle versioni mantiene una storia completa dei dataset, garantendo riproducibilità e integrità dei dati. Le informazioni sulla provenienza e le capacità di rollback aiutano a mantenere il contesto e le relazioni tra gli esperimenti. Inoltre, controlli di accesso granulare e registri di audit assicurano una collaborazione sicura garantendo la conformità a standard normativi come HIPAA e GDPR. Queste funzionalità supportano collettivamente flussi di lavoro scientifici complessi e la gestione di dati su larga scala, rendendo la ricerca più efficiente e affidabile.
Il replatforming dei dati scientifici consiste nello spostare i dati grezzi da silos isolati di fornitori a un ambiente unificato basato sul cloud. Questo processo libera i dati contestualizzandoli per casi d'uso scientifici, rendendoli più accessibili e interoperabili. Riprogrammando i dati, i laboratori possono automatizzare più efficacemente l'assemblaggio e la gestione dei dati, abilitando l'automazione di laboratorio di nuova generazione. L'ambiente dati unificato supporta analisi avanzate e applicazioni di IA, che si basano su dati ben strutturati e contestualizzati. Questa trasformazione migliora l'utilità dei dati, riduce gli errori manuali e accelera le intuizioni scientifiche, migliorando la produttività e accelerando i cicli di ricerca e sviluppo.
Il replatforming dei dati scientifici consiste nello spostare i dati grezzi da silos di fornitori isolati a un ambiente unificato e cloud-native progettato specificamente per applicazioni scientifiche. Questo processo libera i dati da formati e strutture proprietarie, consentendo la contestualizzazione e l'integrazione attraverso diversi casi d'uso scientifici. Automatizzando l'assemblaggio e l'organizzazione dei dati, il replatforming facilita l'automazione e la gestione dei dati di laboratorio di nuova generazione. Gli scienziati possono accedere a dataset armonizzati e di alta qualità che supportano analisi avanzate e applicazioni di IA. Questa trasformazione migliora la liquidità dei dati, riduce la gestione manuale e accelera la generazione di insight azionabili, migliorando l'efficienza della ricerca e la velocità dell'innovazione.
L'utilizzo della replica automatizzata dei dati nella gestione dei flussi di dati finanziari offre significativi vantaggi in termini di costi. Riduce la necessità di interventi manuali nel trasferimento e nella riconciliazione dei dati, abbassando i costi del lavoro e minimizzando gli errori umani che possono portare a correzioni costose. L'automazione semplifica i flussi di lavoro dei dati, diminuendo la complessità e i costi generali associati alla manutenzione di più sistemi di dati. Questa efficienza riduce le spese infrastrutturali e operative. Inoltre, fornendo una sincronizzazione dei dati in tempo reale, aiuta a prevenire ritardi ed errori che potrebbero causare sanzioni finanziarie o opportunità perse, risparmiando denaro e migliorando l'efficienza operativa complessiva.
La provenienza dei dati fornisce una mappa dettagliata del flusso dei dati dalla loro origine attraverso varie trasformazioni fino alla destinazione finale, come gli strumenti di business intelligence. Questa visibilità aiuta le organizzazioni a comprendere le dipendenze e l'impatto delle modifiche ai dati, facilita la risoluzione dei problemi quando si verificano e garantisce la conformità alle politiche di governance dei dati. Avendo una provenienza end-to-end a livello di colonna senza configurazione manuale, i team possono identificare rapidamente dove si verificano problemi di qualità dei dati e mantenere la fiducia nei propri asset dati.
Migliora la gestione dei dati sfruttando l'aggregazione automatica dei dati nelle piattaforme AI. 1. Collega la piattaforma alle tue diverse fonti di dati. 2. Consenti alla piattaforma di raccogliere e consolidare automaticamente i dati. 3. Elimina gli errori di inserimento manuale tramite l'automazione. 4. Assicura che i dati siano continuamente aggiornati e affidabili per analisi e report accurati.
Una piattaforma affidabile per la gestione dei dati di ricerca dovrebbe offrire funzionalità di sicurezza di livello aziendale per proteggere i dati sperimentali sensibili. Ciò include la conformità a standard di sicurezza riconosciuti come la certificazione SOC 2 Type II, che garantisce controlli rigorosi sulla privacy dei dati e sulla disponibilità del sistema. La piattaforma dovrebbe offrire archiviazione sicura dei dati, crittografia sia a riposo che in transito, e permessi di accesso controllati per prevenire accessi non autorizzati. Inoltre, la flessibilità di integrare i propri modelli linguistici di grandi dimensioni (LLM) o fonti di dati può migliorare il controllo sull'ambiente dati. Backup regolari e la capacità di mantenere copie aggiornate di tutti i dati sperimentali sono fondamentali per prevenire la perdita di dati e garantire l'integrità dei dati.
Garantire l'integrità e la professionalità nella gestione dei dati di imaging medico comporta il rigoroso rispetto delle leggi sulla privacy e degli standard etici, inclusi processi approfonditi di de-identificazione per rimuovere le informazioni dei pazienti. Richiede inoltre pratiche trasparenti di gestione dei dati, archiviazione sicura e accesso controllato ai dataset. Collaborazioni con partner esperti che danno priorità alla qualità dei dati e alla conformità garantiscono ulteriormente che la ricerca venga condotta in modo responsabile, mantenendo la fiducia e permettendo lo sviluppo di soluzioni di IA clinicamente affidabili.
L'estrazione automatica dei dati migliora l'efficienza dei sistemi di acquisizione elettronica dei dati (EDC) semplificando il processo di raccolta e inserimento dei dati degli studi clinici. Invece di inserire manualmente i dati, operazione che richiede tempo ed è soggetta a errori, l'estrazione automatica preleva direttamente le informazioni rilevanti da varie fonti come cartelle cliniche, referti di laboratorio o sistemi di imaging. Ciò riduce il rischio di errori umani e accelera la disponibilità dei dati all'interno dell'EDC. Inoltre, integrando una validazione intelligente durante l'estrazione, il sistema garantisce che solo dati accurati e conformi al protocollo vengano inseriti nell'EDC. Questo porta a meno richieste di dati, un blocco del database più rapido e un'efficienza complessiva migliorata nella gestione degli studi.