Step 1
Machine-Ready Briefs
AI translates unstructured needs into a technical, machine-ready project request.
We use cookies to improve your experience and analyze site traffic. You can accept all cookies or only essential ones.
Stop browsing static lists. Tell Bilarna your specific needs. Our AI translates your words into a structured, machine-ready request and instantly routes it to verified Data Management Solutions experts for accurate quotes.
AI translates unstructured needs into a technical, machine-ready project request.
Compare providers using verified AI Trust Scores & structured capability data.
Skip the cold outreach. Request quotes, book demos, and negotiate directly in chat.
Filter results by specific constraints, budget limits, and integration requirements.
Eliminate risk with our 57-point AI safety check on every provider.
Verified companies you can talk to directly

Elementary is the control plane for data and AI reliability. It unifies observability, quality, governance, and discovery, enabling teams to deliver trusted data at scale in the AI era. Engineers work in code, business users get AI-first validation and exploration. Trusted by teams at Elastic, RGA,

The Tetra Scientific Data and AI Platform is the only vendor-neutral, open, cloud-native platform purpose-built for science. Get next-generation lab data automation, scientific data management, and foundational building blocks of Scientific AI. Start your AI journey.
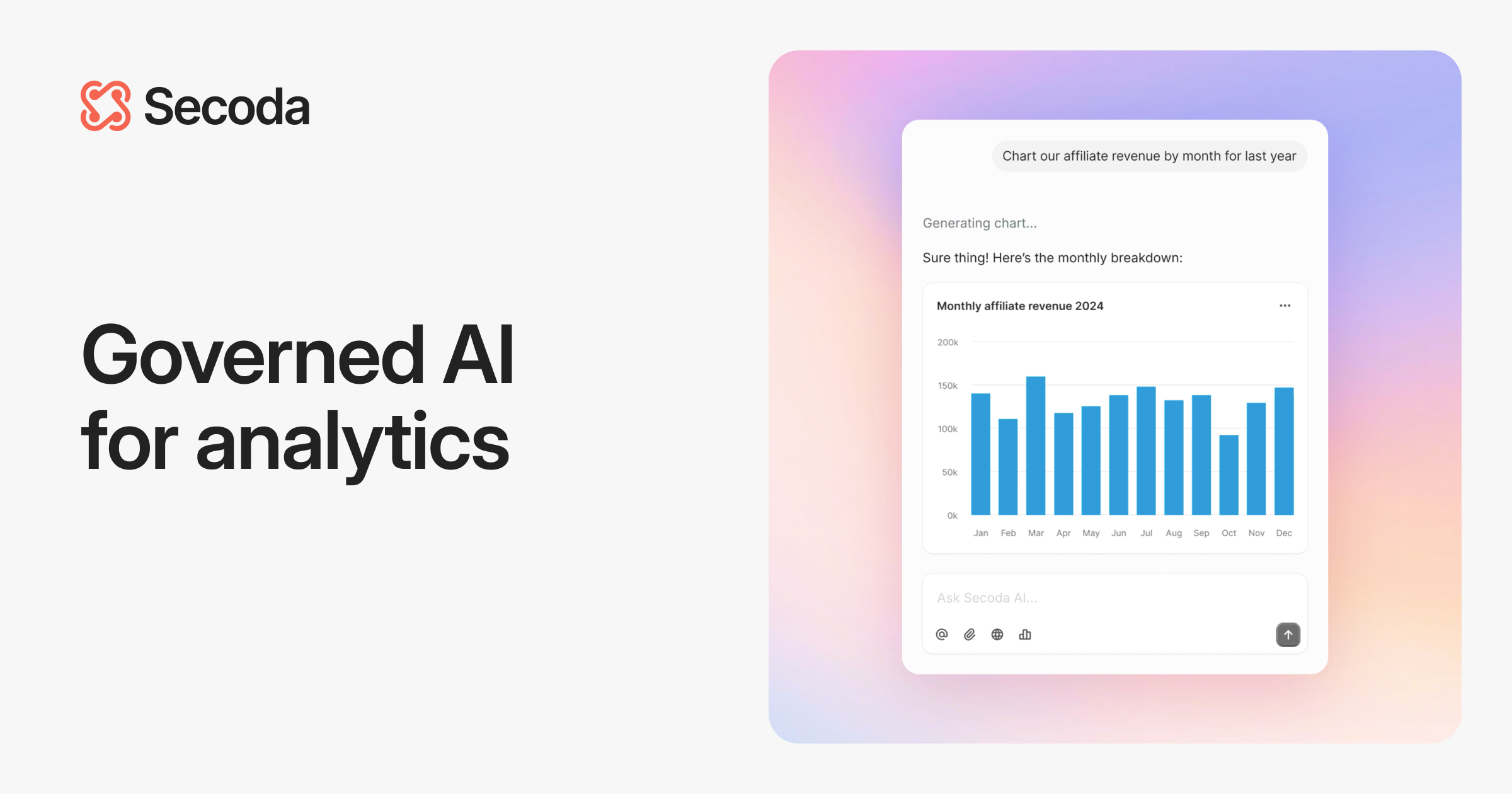
Redefine data governance and trust with AI built on a foundation of data cataloging, lineage, observability, and quality —all enriched by your business context.
Run a free AEO + signal audit for your domain.
AI Answer Engine Optimization (AEO)
List once. Convert intent from live AI conversations without heavy integration.
Data management solutions are integrated platforms and services that govern the collection, storage, organization, and utilization of an organization's data assets. They encompass data governance, quality control, integration pipelines, security protocols, and master data management. These solutions empower businesses to unlock actionable insights, ensure regulatory compliance, and drive data-informed strategic decisions.
Organizations establish governance policies, quality standards, and architectural requirements for their data lifecycle and analytics goals.
Specialized software is deployed for data integration, warehousing, quality management, and security to create a unified source of truth.
Cleansed, governed data is made accessible for analytics, business intelligence, and operational applications to fuel decision-making.
Ensures adherence to regulations like GDPR and SOX by implementing robust data lineage, audit trails, and access controls across financial datasets.
Integrates disparate EHR and patient management systems to create unified patient records, enabling improved care coordination and analytics.
Unifies customer data from web, mobile, and CRM touchpoints to drive personalized marketing, inventory forecasting, and customer journey optimization.
Manages and analyzes high-volume sensor data from production lines to enable predictive maintenance, quality control, and supply chain optimization.
Governs product usage data to ensure clean, reliable metrics for customer behavior analysis, feature adoption tracking, and churn prediction.
Bilarna evaluates every Data Management Solutions provider through a proprietary 57-point AI Trust Score. This score rigorously assesses technical certifications, portfolio complexity, client reference checks, and data security compliance. We continuously monitor performance metrics to ensure listed providers maintain the highest standards of expertise and reliability.
Costs vary significantly based on scope, ranging from project-based consulting fees to annual SaaS licenses and implementation services. Enterprise deployments often involve six-figure investments, while focused solutions for mid-market companies can start in the tens of thousands. Key cost drivers include data volume, integration complexity, and required security compliance levels.
Data management is the broader practice of handling data throughout its lifecycle, including integration, quality, and storage. Data governance is a core subset focusing specifically on the policies, standards, and ownership that ensure data is managed as a formal asset. Governance defines the rules, while management executes the technical and operational processes.
Implementation timelines range from 3-6 months for foundational projects to over 12 months for enterprise-wide transformations. Duration depends on data ecosystem complexity, legacy system integration requirements, and the scope of governance policies being established. A phased rollout starting with a critical data domain is a common best practice.
Common pitfalls include underestimating data integration complexity, overlooking scalability for future data growth, and neglecting the provider's expertise in your specific industry compliance needs. Focusing solely on technology without assessing the vendor's change management and support capabilities also leads to implementation challenges and suboptimal ROI.
Essential features include automated data quality and profiling, metadata management and lineage tracking, cloud-native and hybrid deployment options, and robust security with fine-grained access controls. Look for platforms supporting real-time data ingestion, API-led connectivity, and embedded analytics capabilities to future-proof your investment.
Yes, modern paywall solutions are designed to be compatible with both iOS and Android mobile applications. This cross-platform compatibility ensures that developers can implement a single paywall system across different devices and operating systems without needing separate solutions. It simplifies management and provides a consistent user experience regardless of the platform, making it easier to maintain and optimize monetization strategies.
To understand data upload limits and payment requirements on analytics platforms, follow these steps: 1. Review the platform's account types, such as free and paid plans. 2. Check the data upload limits for each plan; free accounts often have row limits per upload. 3. Determine if a credit card is required for free or paid accounts. 4. Understand the cancellation policy for paid subscriptions, which usually allows cancellation at any time.
Typically, after an initial trial period—often around seven days—business management software platforms do not charge monthly fees or enforce minimum usage requirements. Instead, continued use is contingent upon subscribing to a paid plan. This approach allows users to evaluate the software's features risk-free before committing financially. It is advisable to review the specific pricing details and terms on the provider's official website to understand any conditions related to payment plans, as these can vary between services.
Yes, a Laboratory Information Management System is designed to integrate seamlessly with various software systems and devices. This integration capability allows automatic transfer of test results and other data between the LIMS and external applications, reducing manual data entry and minimizing errors. It supports connectivity with laboratory instruments, billing systems, and other business software, enabling a unified workflow. Users can access test results and invoices from any device, ensuring flexibility and convenience. Such integrations enhance data accuracy, improve operational efficiency, and facilitate better communication across different platforms used within the laboratory environment.
Yes, AI dental receptionists can integrate seamlessly with most major practice management systems (PMS) that offer online appointment pages or APIs. This integration allows the AI to book appointments directly into your existing system, pull customer form responses from your CRM, and route calls to the correct clinic and calendar. Such integration ensures that all patient interactions are synchronized with your practice’s workflow, improving efficiency and reducing manual data entry errors.
Yes, AI design engineering tools are designed for seamless integration with existing CAD, BIM, and project management software. This compatibility ensures that engineers can continue using their preferred tools without disrupting established workflows. The integration facilitates data exchange and collaboration, enhancing efficiency and enabling teams to leverage AI capabilities alongside their current systems.
Yes, AI planning platforms are designed to integrate seamlessly with existing trucking management tools and portals. This means there is no need to replace current systems, allowing fleets to enhance their operations without disrupting established workflows. Integration is typically facilitated through pre-built connectors that link the AI platform with the fleet's existing data sources and software. This approach enables a fast start and real impact, as fleets can deploy AI-driven planning solutions risk-free and begin seeing results within a short timeframe, often within a month. Continuous support is also provided to ensure smooth integration and ongoing optimization.
Yes, AI RFP software typically integrates with a wide range of existing business tools such as CRM platforms, collaboration software, cloud storage services, and knowledge management systems. This seamless integration allows users to leverage their current data sources and workflows without disruption. Regarding security, reputable AI RFP solutions prioritize data protection through measures like end-to-end encryption, compliance with standards such as SOC 2, GDPR, and CCPA, and role-based access controls. Data is never shared with third parties, ensuring confidentiality and compliance with privacy regulations.
Yes, AI timekeeping software is designed to integrate seamlessly with existing legal practice management tools. This integration allows the software to draft and release time entries directly into platforms commonly used by law firms, such as Clio, MyCase, and Filevine. By working within the tools lawyers already use, the software eliminates the need for workflow changes, making adoption easier and more efficient. This connectivity ensures that time tracking and billing processes are streamlined, enabling law firms to increase billable hours and improve overall productivity without disrupting their current systems.
Yes, many AI-powered browsers built on Chromium technology are compatible with Chrome extensions, allowing users to continue using their favorite add-ons without interruption. These browsers often support seamless import of existing browser data such as bookmarks, passwords, and extensions from Chrome, making the transition smooth and convenient. This compatibility ensures that users do not lose their personalized settings or tools when switching to an AI-enabled browser. By combining AI capabilities with familiar browser features, users can enhance productivity while maintaining their preferred browsing environment.