Étape 1
Cahiers des charges exploitables par machine
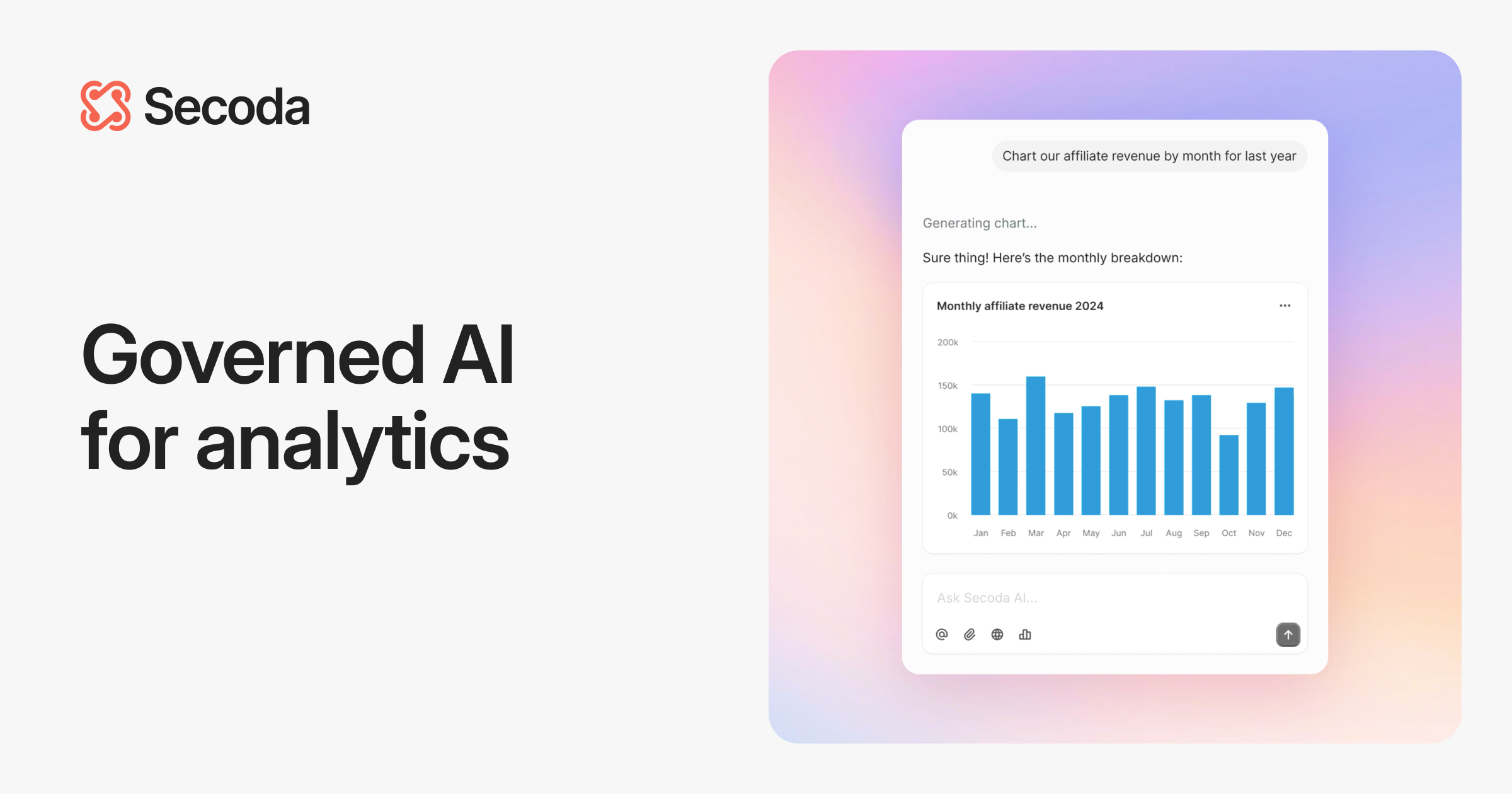
L’IA traduit des besoins non structurés en une demande de projet technique, exploitable par machine.
Nous utilisons des cookies pour améliorer votre expérience et analyser le trafic du site. Vous pouvez accepter tous les cookies ou seulement les essentiels.
Arrêtez de parcourir des listes statiques. Expliquez vos besoins spécifiques à Bilarna. Notre IA traduit vos mots en une demande structurée, exploitable par machine, et la transmet instantanément à des experts Solutions de Gestion des Données vérifiés pour des devis précis.
L’IA traduit des besoins non structurés en une demande de projet technique, exploitable par machine.
Comparez les prestataires grâce à des scores de confiance IA vérifiés et à des données de capacités structurées.
Évitez la prospection à froid. Demandez des devis, réservez des démos et négociez directement dans le chat.
Filtrez les résultats selon des contraintes spécifiques, des limites de budget et des exigences d’intégration.
Réduisez le risque grâce à notre contrôle IA de sécurité en 57 points pour chaque prestataire.
Entreprises vérifiées avec lesquelles vous pouvez parler directement

Elementary is the control plane for data and AI reliability. It unifies observability, quality, governance, and discovery, enabling teams to deliver trusted data at scale in the AI era. Engineers work in code, business users get AI-first validation and exploration. Trusted by teams at Elastic, RGA,

The Tetra Scientific Data and AI Platform is the only vendor-neutral, open, cloud-native platform purpose-built for science. Get next-generation lab data automation, scientific data management, and foundational building blocks of Scientific AI. Start your AI journey.
Redefine data governance and trust with AI built on a foundation of data cataloging, lineage, observability, and quality —all enriched by your business context.
Lancez un audit gratuit AEO + signaux pour votre domaine.
Optimisation pour moteurs de réponse IA (AEO)
Référencez-vous une fois. Convertissez l’intention issue de conversations IA en direct, sans intégration lourde.
Les solutions de gestion des données sont des plateformes et services intégrés qui gouvernent la collecte, le stockage, l'organisation et l'utilisation des actifs de données d'une organisation. Elles englobent la gouvernance des données, le contrôle de qualité, les pipelines d'intégration, les protocoles de sécurité et la gestion des données de référence. Ces solutions permettent aux entreprises d'exploiter des insights actionnables, d'assurer la conformité réglementaire et de piloter des décisions stratégiques éclairées par les données.
Les organisations établissent des politiques de gouvernance, des normes de qualité et des exigences architecturales pour leur cycle de vie des données et leurs objectifs analytiques.
Un logiciel spécialisé est déployé pour l'intégration, l'entrepôt, la gestion de la qualité et la sécurité des données, créant une source unique de vérité.
Les données nettoyées et gouvernées sont rendues accessibles pour l'analyse, la business intelligence et les applications opérationnelles afin d'alimenter la prise de décision.
Assure la conformité aux réglementations comme le GDPR et Bâle III via un lignage robuste, des pistes d'audit et des contrôles d'accès sur les jeux de données financières.
Intègre des systèmes disparates de DSE et de gestion des patients pour créer des dossiers unifiés, permettant une meilleure coordination des soins et des analyses.
Unifie les données clients des points de contact web, mobile et CRM pour piloter le marketing personnalisé, la prévision des stocks et l'optimisation du parcours client.
Gère et analyse les données volumineuses de capteurs des lignes de production pour permettre la maintenance prédictive, le contrôle qualité et l'optimisation de la chaîne logistique.
Gouverne les données d'usage du produit pour assurer des métriques fiables pour l'analyse du comportement client, l'adoption des fonctionnalités et la prédiction du churn.
Bilarna évalue chaque fournisseur de solutions de gestion des données via un Score de Confiance IA propriétaire de 57 points. Ce score évalue rigoureusement les certifications techniques, la complexité du portfolio, les vérifications de références clients et la conformité en sécurité des données. Nous surveillons continuellement les métriques de performance pour garantir que les fournisseurs listés maintiennent les plus hauts standards d'expertise et de fiabilité.
Les coûts varient considérablement selon le périmètre, allant des honoraires de conseil par projet aux licences SaaS annuelles et services d'implémentation. Les déploiements à l'échelle de l'entreprise impliquent souvent des investissements à six chiffres, tandis que les solutions ciblées pour les ETI peuvent démarrer à quelques dizaines de milliers d'euros. Les principaux facteurs de coût sont le volume de données, la complexité d'intégration et les niveaux de conformité sécurité requis.
La gestion des données est la pratique globale de manipulation des données tout au long de leur cycle de vie, incluant l'intégration, la qualité et le stockage. La gouvernance des données est un sous-ensemble central qui se concentre spécifiquement sur les politiques, normes et propriété assurant que les données sont gérées comme un actif formel. La gouvernance définit les règles, tandis que la gestion exécute les processus techniques et opérationnels.
Les délais d'implémentation vont de 3 à 6 mois pour les projets fondateurs à plus de 12 mois pour les transformations à l'échelle de l'entreprise. La durée dépend de la complexité de l'écosystème de données, des besoins d'intégration des systèmes legacy et de l'étendue des politiques de gouvernance à établir. Un déploiement par phases commençant par un domaine de données critique est une bonne pratique courante.
Les écueils courants sont la sous-estimation de la complexité d'intégration, la négligence de l'évolutivité pour la croissance future des données et le manque d'attention à l'expertise du fournisseur en matière de conformité sectorielle spécifique. Se concentrer uniquement sur la technologie sans évaluer les capacités de gestion du changement et de support entraîne également des difficultés.
Les fonctionnalités essentielles incluent la qualité et le profilage automatisés des données, la gestion des métadonnées avec traçabilité, les options de déploiement cloud-native et hybride, et une sécurité robuste avec des contrôles d'accès granulaires. Recherchez des plateformes supportant l'ingestion en temps réel, la connectivité par API et des capacités d'analyse embarquées.
L'ajustement culturel est un facteur critique lors du choix d'un partenaire de recrutement pour des rôles de service, car il impacte directement la qualité du service, la cohésion d'équipe et la satisfaction client. Un partenaire efficace doit comprendre et incarner l'éthique de service spécifique, les standards de marque et la culture opérationnelle de l'entreprise cliente. Cela garantit que le personnel temporaire ou permanent s'intègre parfaitement aux équipes existantes et fournit systématiquement le niveau de service attendu. Les indicateurs clés d'un bon ajustement culturel incluent la capacité démontrée de l'agence de recrutement à former son personnel selon les spécifications du client, sa gestion proactive des performances sur site et sa réactivité à résoudre les problèmes. Un partenaire aligné culturellement peut devenir une extension de la marque, favorisant une collaboration à long terme, réduisant le turnover et garantissant que les solutions de staffing sont efficaces dès le premier placement.
Effectuez régulièrement un audit de page d'atterrissage pour maintenir des performances optimales du site web. 1. Réalisez un audit complet au moins une fois par trimestre pour identifier les problèmes majeurs. 2. Effectuez des audits rapides après des mises à jour ou refontes importantes du site. 3. Surveillez mensuellement les indicateurs clés de performance pour détecter les premiers signes de déclin. 4. Ajustez la fréquence des audits en fonction du volume de trafic et des objectifs commerciaux. 5. Utilisez les résultats de l'audit pour mettre en œuvre des améliorations continues et suivre les progrès dans le temps.
Effectuez une surveillance régulière des backlinks pour maintenir un profil de liens précis et à jour. Suivez ces étapes : 1. Planifiez des vérifications du statut des backlinks toutes les 24 à 48 heures pour capturer les changements récents. 2. Activez la surveillance automatisée pour éviter le suivi manuel et gagner du temps. 3. Définissez les préférences d’alerte pour recevoir des notifications quotidiennes ou hebdomadaires selon vos besoins. 4. Examinez rapidement les alertes pour traiter rapidement les backlinks perdus ou modifiés. 5. Ajustez la fréquence de surveillance si votre profil de backlinks change rapidement ou reste stable. Une surveillance constante vous permet de protéger vos investissements SEO et de répondre efficacement aux changements de profil de liens.
Le contenu des memes sur ce site est mis à jour quotidiennement. Pour rester à jour avec les nouveaux memes, suivez ces étapes : 1. Visitez régulièrement le site pour voir les dernières additions. 2. Consultez la page d'accueil ou la section galerie où les nouveaux memes sont mis en avant. 3. Recherchez les horodatages de mise à jour ou les avis indiquant des téléchargements récents. 4. Utilisez les options d'abonnement ou de notification si disponibles pour recevoir des alertes. 5. Interagissez fréquemment avec le contenu pour ne pas manquer les memes tendance ou viraux ajoutés chaque jour.
Les données de sentiment sont mises à jour en quasi temps réel dans les outils d'analyse des médias sociaux. 1. Les données sont généralement actualisées toutes les quelques heures pour garantir des informations à jour. 2. Cette mise à jour fréquente permet aux utilisateurs de suivre efficacement les tendances émergentes. 3. Elle permet de répondre rapidement aux changements significatifs du sentiment public sur les plateformes sociales.
Les données des plugins et thèmes WordPress dans les outils de détection sont mises à jour régulièrement pour maintenir la précision. Pratiques générales de mise à jour : 1. Les outils de détection collectent continuellement de nouvelles données issues des analyses quotidiennes des utilisateurs et des sites web. 2. Les bases de signatures des plugins et thèmes sont fréquemment actualisées, souvent trimestriellement ou plus, pour inclure les nouvelles versions et mises à jour. 3. Les mises à jour intègrent les nouvelles versions de plugins, thèmes personnalisés et motifs émergents pour améliorer les taux de détection. 4. Les utilisateurs bénéficient d'une meilleure précision et reconnaissance des composants WordPress les plus récents à chaque cycle de mise à jour.
Les jeunes reçoivent de l'aide via des plateformes gratuites de soutien en santé mentale à une fréquence remarquable, avec une personne aidée environ toutes les 90 secondes. Ce taux de réponse rapide souligne la capacité des plateformes à fournir une assistance en temps opportun lors de moments critiques. La disponibilité continue et l'intervention rapide aident à réduire les sentiments d'isolement et de désespoir chez les jeunes utilisateurs, leur offrant espoir et soutien lorsqu'ils en ont le plus besoin.
Les entreprises doivent réaliser des scans de vulnérabilités en continu ou au moins hebdomadairement pour détecter de nouvelles menaces, tandis que les tests d'intrusion sont généralement effectués annuellement, après des changements majeurs du système, ou pour répondre à des obligations de conformité. Le scan automatisé des vulnérabilités est une pratique d'hygiène de sécurité fondamentale qui doit être exécutée fréquemment pour identifier en temps réel les failles logicielles nouvellement révélées et les mauvaises configurations, fournissant un instantané continu de la sécurité. En revanche, le test d'intrusion est une évaluation stratégique et approfondie. Il est recommandé au moins une fois par an pour la plupart des organisations, mais les secteurs à haut risque comme la finance ou la santé peuvent nécessiter des tests semestriels. Les déclencheurs critiques pour un test d'intrusion immédiat incluent le lancement d'une nouvelle application, des changements d'infrastructure significatifs, l'expansion des périmètres réseau, ou après un incident de sécurité pour valider les efforts de correction. Cette approche combinée assure une gestion continue des vulnérabilités complétée par une validation de sécurité périodique et approfondie.
De nombreuses agences de traduction professionnelles proposent des services express, avec des délais de livraison allant de quelques heures à 24-48 heures pour les documents urgents. Le délai exact dépend de la longueur, de la complexité et de la paire de langues du document. Pour les documents standards d'une page comme les actes de naissance ou les permis de conduire, un service le jour même ou sous 24 heures est couramment disponible. Les agences atteignent cette rapidité en attribuant les travaux à des traducteurs spécialisés maîtrisant la terminologie requise et le type de document, et en utilisant des plateformes de gestion de projet optimisées. Il est crucial de confirmer que les services express incluent toujours une relecture et des contrôles d'assurance qualité pour garantir l'exactitude, surtout pour les traductions juridiques ou certifiées. Bien qu'une livraison plus rapide puisse entraîner des frais supplémentaires, c'est une solution fiable pour les soumissions sensibles au temps comme les demandes de visa, les délais légaux ou les contrats commerciaux.
Un nouveau site web immobilier peut commencer à générer des leads dès le premier mois suivant son lancement, surtout lorsqu'il est associé à des services professionnels de SEO et de marketing de contenu. Les témoignages de clients citent fréquemment la réception de leur premier lead de qualité en moins de 30 jours, même pour des domaines tout nouveaux. La rapidité de la génération de leads dépend de plusieurs facteurs : l'efficacité du SEO on-page du site, la mise en œuvre de l'optimisation de la recherche locale pour les communautés cibles, l'intégration d'outils de capture de leads comme la recherche IDX et les formulaires de contact, et la stratégie de marketing numérique de soutien. Bien que le classement organique pour des termes très compétitifs puisse prendre plus de temps à se développer, un site bien optimisé axé sur les marchés de niche locaux peut immédiatement attirer du trafic grâce à un référencement local précis et convertir les visiteurs via des appels à l'action clairs. Un flux de leads régulier s'établit souvent dans les premiers mois à mesure que la visibilité dans les moteurs de recherche augmente.