Step 1
Comparison Shortlist
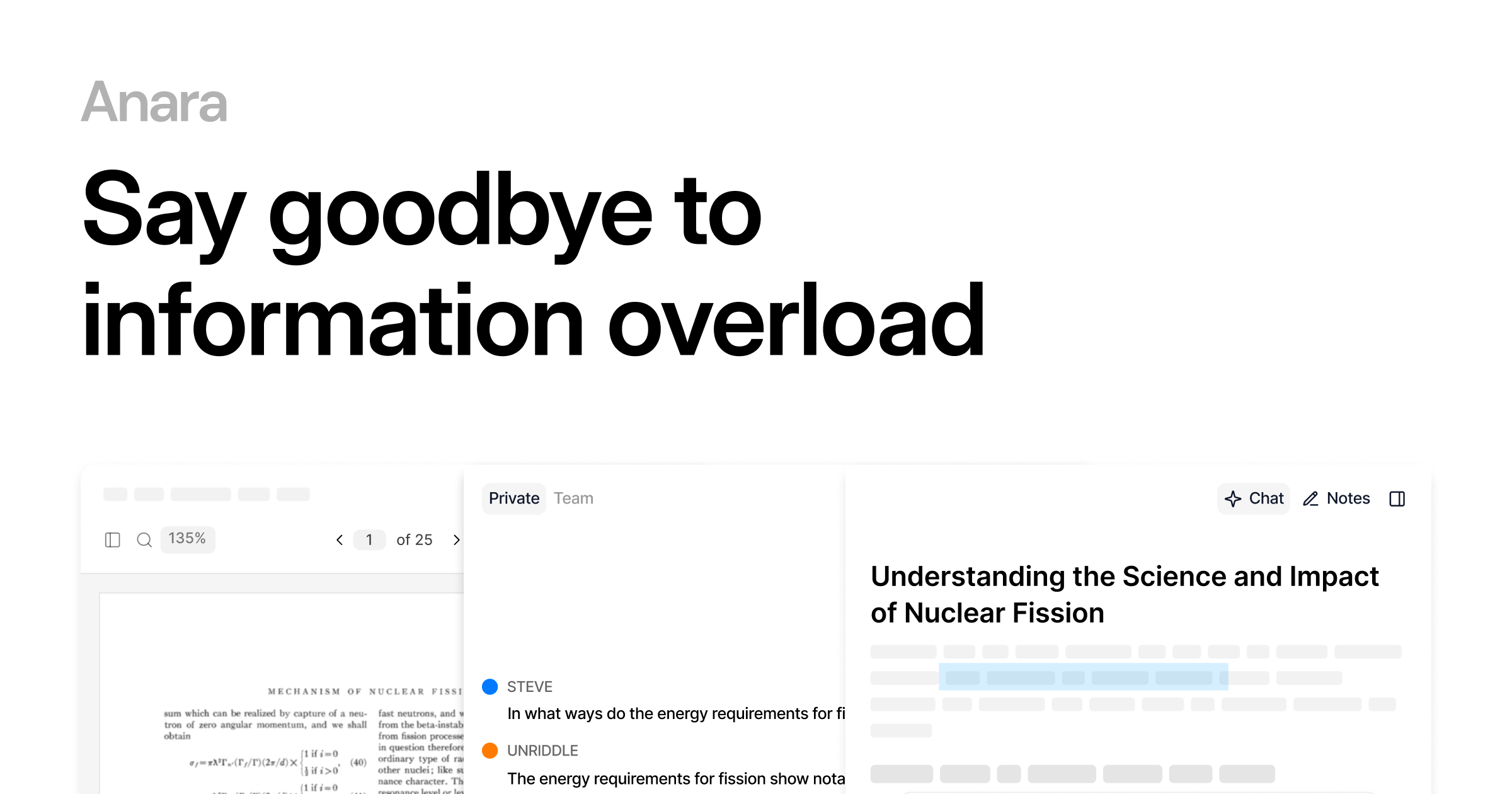
Cahiers des charges exploitables par machine : l’IA transforme des besoins flous en demande technique de projet.
Nous utilisons des cookies pour améliorer votre expérience et analyser le trafic du site. Vous pouvez accepter tous les cookies ou seulement les essentiels.
Arrêtez de parcourir des listes statiques. Expliquez vos besoins spécifiques à Bilarna. Notre IA traduit vos mots en une demande structurée, exploitable par machine, puis l’achemine instantanément vers des experts Gestion des Données de Recherche vérifiés pour obtenir des devis précis.
Cahiers des charges exploitables par machine : l’IA transforme des besoins flous en demande technique de projet.
Scores de confiance vérifiés : comparez les prestataires grâce à notre contrôle de sécurité IA en 57 points.
Accès direct : évitez la prospection à froid. Demandez des devis et réservez des démos directement dans le chat.
Matching précis : filtrez les correspondances selon des contraintes spécifiques, le budget et les intégrations.
Réduction du risque : des signaux de capacité validés réduisent la friction d’évaluation & le risque.
Classés par score de confiance IA & capacité


Lancez un audit gratuit AEO + signaux pour votre domaine.
Optimisation pour moteurs de réponse IA (AEO)
List once. Convert intent from live AI conversations without heavy integration.
La Gestion des Données de Recherche (GDR) désigne l'ensemble des processus visant à organiser, stocker, sécuriser et partager les données tout au long du cycle de vie d'un projet scientifique. Elle fait appel à des technologies telles que les cahiers de laboratoire électroniques (ELN), les entrepôts de données, les standards de métadonnées et les systèmes de contrôle d'accès, et est cruciale dans des domaines comme la santé, les sciences humaines et sociales, la physique ou l'agronomie. Ses principaux avantages sont d'assurer l'intégrité et la reproductibilité des données, de se conformer aux exigences des financeurs comme l'ANR ou aux règlements comme le RGPD, de faciliter la collaboration inter-équipes et de valoriser le patrimoine numérique de la recherche.
Les prestataires de solutions de Gestion des Données de Recherche comprennent des éditeurs de logiciels spécialisés comme Nakala, DSpace-CRIS ou OpenEdition; des géants du cloud comme OVHcloud avec des offres dédiées à la recherche; ainsi que des sociétés de services en ingénierie des données. Beaucoup de ces acteurs disposent de certifications en sécurité informatique et conçoivent des solutions conformes aux cadres nationaux et européens, tels que le Plan National pour la Science Ouverte ou les principes FAIR pour les données.
La Gestion des Données de Recherche fonctionne via un workflow structuré, depuis la planification et la documentation des données jusqu'à leur stockage sécurisé dans des dépôts cloud ou sur site, puis leur partage contrôlé ou leur archivage pérenne. Les modèles tarifaires courants sont les abonnements SaaS, souvent échelonnés selon le volume de stockage ou le nombre de chercheurs, avec des coûts allant de formules individuelles à des contrats institutionnels annuels. Le déploiement peut prendre de quelques semaines pour des outils cloud à plusieurs mois pour des infrastructures complexes. Les prestataires proposent généralement des parcours d'achat numériques, incluant des demandes de devis en ligne, des démonstrations de plateforme et des périodes d'essai permettant de tester les fonctionnalités avec des jeux de données réels.
Gestion des Données de Recherche — optimisez la collecte, le stockage et le partage pour l'intégrité scientifique. Découvrez et comparez des fournisseurs vérifiés avec des insights alimentés par l'IA sur Bilarna.
View Gestion des Données de Recherche providersDes services efficaces de gestion des données de recherche garantissent un stockage sécurisé, une documentation appropriée et un partage facile des données de recherche.
View Services de Données de Recherche providersSolutions de stockage et d'analyse de données intègrent gestion et analytique pour générer des insights. Comparez les fournisseurs B2B vérifiés sur le marché de Bilarna avec le Score de Confiance IA à 57 points.
View Solutions Stockage et Analyse Données providersLes plateformes de données alimentées par l’IA pour la recherche scientifique offrent plusieurs fonctionnalités clés qui améliorent la gestion et l’accessibilité des données. Cela inclut un balisage avancé des métadonnées et un indexage qui organisent les données structurées et non structurées pour améliorer la précision des recherches. Les capacités de recherche assistée par IA permettent aux chercheurs de localiser rapidement les ensembles de données pertinents, réduisant ainsi considérablement le temps de recherche. Le suivi automatique des versions maintient un historique complet des ensembles de données, garantissant la reproductibilité et l’intégrité des données. Les informations sur la lignée des données et les capacités de retour en arrière aident à maintenir le contexte et les relations entre les expériences. De plus, des contrôles d’accès granulaires et des journaux d’audit assurent une collaboration sécurisée tout en garantissant la conformité aux normes réglementaires telles que HIPAA et RGPD. Ces fonctionnalités soutiennent collectivement des flux de travail scientifiques complexes et la gestion de données à grande échelle, rendant la recherche plus efficace et fiable.
La combinaison de la technologie IA avec la gestion humaine des données exploite les forces des deux pour améliorer la précision et la fiabilité des données. L'IA peut traiter rapidement de grands volumes de données et identifier des modèles ou des changements en temps réel, tandis que les experts humains fournissent une revue nuancée et une assurance qualité pour garantir l'exhaustivité et la justesse. Cette approche hybride aboutit à des données plus fiables, réduit les erreurs et maintient des normes élevées que les systèmes purement automatisés pourraient manquer. De plus, elle permet une gestion des données évolutive et efficace qui équilibre la rapidité technologique avec le jugement humain, soutenant finalement de meilleures décisions commerciales et des relations clients améliorées.
La replatformisation des données scientifiques consiste à déplacer les données brutes issues de silos fournisseurs isolés vers un environnement unifié basé sur le cloud. Ce processus libère les données en les contextualisant pour des cas d'utilisation scientifique, les rendant plus accessibles et interopérables. En replatformisant les données, les laboratoires peuvent automatiser plus efficacement l'assemblage et la gestion des données, permettant ainsi une automatisation de laboratoire de nouvelle génération. L'environnement de données unifié prend en charge des analyses avancées et des applications d'IA, qui dépendent de données bien structurées et contextualisées. Cette transformation améliore l'utilité des données, réduit les erreurs de manipulation manuelle et accélère les insights scientifiques, améliorant ainsi la productivité et accélérant les cycles de recherche et développement.
Utilisez un assistant de recherche de données IA pour rationaliser votre recherche en suivant ces étapes : 1. Définissez vos objectifs de recherche et saisissez des requêtes spécifiques dans l'assistant. 2. Laissez l'assistant collecter et analyser rapidement des données provenant de plusieurs sources. 3. Examinez les résultats synthétisés et les insights fournis. 4. Appliquez les résultats pour affiner vos hypothèses de recherche ou soutenir des décisions basées sur des preuves.
Une plateforme fiable de gestion des données de recherche doit offrir des fonctionnalités de sécurité de niveau entreprise pour protéger les données expérimentales sensibles. Cela inclut la conformité à des normes de sécurité reconnues telles que la certification SOC 2 Type II, qui garantit des contrôles rigoureux sur la confidentialité des données et la disponibilité du système. La plateforme doit proposer un stockage sécurisé des données, un chiffrement au repos et en transit, ainsi que des permissions d'accès contrôlées pour empêcher tout accès non autorisé. De plus, la flexibilité d'intégrer vos propres grands modèles de langage (LLM) ou sources de données peut renforcer le contrôle de votre environnement de données. Des sauvegardes régulières et la capacité à conserver des copies à jour de toutes les données expérimentales sont également essentielles pour prévenir la perte de données et assurer l'intégrité des données.
Assurer l'intégrité et le professionnalisme dans la gestion des données d'imagerie médicale implique une stricte conformité aux lois sur la confidentialité et aux normes éthiques, y compris des processus approfondis de dé-identification pour supprimer les informations des patients. Cela nécessite également des pratiques transparentes de gestion des données, un stockage sécurisé et un accès contrôlé aux ensembles de données. La collaboration avec des partenaires expérimentés qui privilégient la qualité des données et la conformité garantit en outre que la recherche est menée de manière responsable, en maintenant la confiance et en permettant le développement de solutions d'IA cliniquement fiables.
La replatformisation des données scientifiques consiste à déplacer les données brutes issues de silos fournisseurs isolés vers un environnement unifié, natif du cloud, conçu spécifiquement pour les applications scientifiques. Ce processus libère les données des formats et structures propriétaires, permettant leur contextualisation et intégration à travers divers cas d'utilisation scientifique. En automatisant l'assemblage et l'organisation des données, la replatformisation facilite l'automatisation et la gestion des données de laboratoire de nouvelle génération. Les scientifiques peuvent accéder à des ensembles de données harmonisés et de haute qualité qui soutiennent l'analyse avancée et les applications d'IA. Cette transformation améliore la fluidité des données, réduit la manipulation manuelle et accélère la génération d'insights exploitables, améliorant ainsi l'efficacité de la recherche et la rapidité d'innovation.
Une plateforme de prévention des pertes de données (DLP) et de gestion de la posture de sécurité des données (DSPM) offre une protection complète des données sensibles dans les environnements SaaS, cloud et autres. Les fonctionnalités clés incluent la numérisation et la découverte de fichiers et documents sensibles grâce à l'apprentissage automatique et à la technologie OCR, la surveillance continue des mauvaises configurations et des expositions à risque, ainsi que des actions de remédiation automatisées telles que la révocation du partage externe, l'application d'étiquettes de classification, la rédaction ou le masquage des champs sensibles, et l'alerte ou la suppression des données. Ces plateformes prennent en charge divers types de données, notamment financières, PCI, PII, PHI et propriétaires, et s'intègrent profondément aux applications SaaS et cloud populaires. Elles permettent également des analyses en temps réel et historiques sans que les données ne quittent le cloud, garantissant la conformité réglementaire et améliorant la visibilité et le contrôle de la posture de sécurité des données.
L'utilisation de la réplication automatisée des données dans la gestion des flux de données financiers offre des avantages significatifs en termes de coûts. Elle réduit le besoin d'intervention manuelle lors du transfert et de la réconciliation des données, ce qui diminue les coûts de main-d'œuvre et minimise les erreurs humaines pouvant entraîner des corrections coûteuses. L'automatisation rationalise les flux de travail des données, réduisant la complexité et les frais généraux liés à la maintenance de plusieurs systèmes de données. Cette efficacité diminue les dépenses d'infrastructure et d'exploitation. De plus, en fournissant une synchronisation des données en temps réel, elle aide à prévenir les retards et erreurs pouvant entraîner des pénalités financières ou des opportunités perdues, économisant ainsi de l'argent et améliorant l'efficacité opérationnelle globale.
La traçabilité des données fournit une carte détaillée du flux des données depuis leur origine, à travers diverses transformations, jusqu'à leur destination finale, comme les outils de business intelligence. Cette visibilité aide les organisations à comprendre les dépendances et l'impact des modifications des données, facilite le dépannage en cas de problèmes et garantit la conformité aux politiques de gouvernance des données. En disposant d'une traçabilité complète au niveau des colonnes sans configuration manuelle, les équipes peuvent rapidement identifier où se produisent les problèmes de qualité des données et maintenir la confiance dans leurs actifs de données.