Étape 1
Cahiers des charges exploitables par machine
L’IA traduit des besoins non structurés en une demande de projet technique, exploitable par machine.
Nous utilisons des cookies pour améliorer votre expérience et analyser le trafic du site. Vous pouvez accepter tous les cookies ou seulement les essentiels.
Arrêtez de parcourir des listes statiques. Expliquez vos besoins spécifiques à Bilarna. Notre IA traduit vos mots en une demande structurée, exploitable par machine, et la transmet instantanément à des experts Collecte Données Vocales et Entraînement Modèles vérifiés pour des devis précis.
L’IA traduit des besoins non structurés en une demande de projet technique, exploitable par machine.
Comparez les prestataires grâce à des scores de confiance IA vérifiés et à des données de capacités structurées.
Évitez la prospection à froid. Demandez des devis, réservez des démos et négociez directement dans le chat.
Filtrez les résultats selon des contraintes spécifiques, des limites de budget et des exigences d’intégration.
Réduisez le risque grâce à notre contrôle IA de sécurité en 57 points pour chaque prestataire.
Entreprises vérifiées avec lesquelles vous pouvez parler directement
Uplift AI is creating an audio dataset of unprecedented scale to unlock new model capabilities across hundreds of low-resource languages.
Lancez un audit gratuit AEO + signaux pour votre domaine.
Optimisation pour moteurs de réponse IA (AEO)
Référencez-vous une fois. Convertissez l’intention issue de conversations IA en direct, sans intégration lourde.
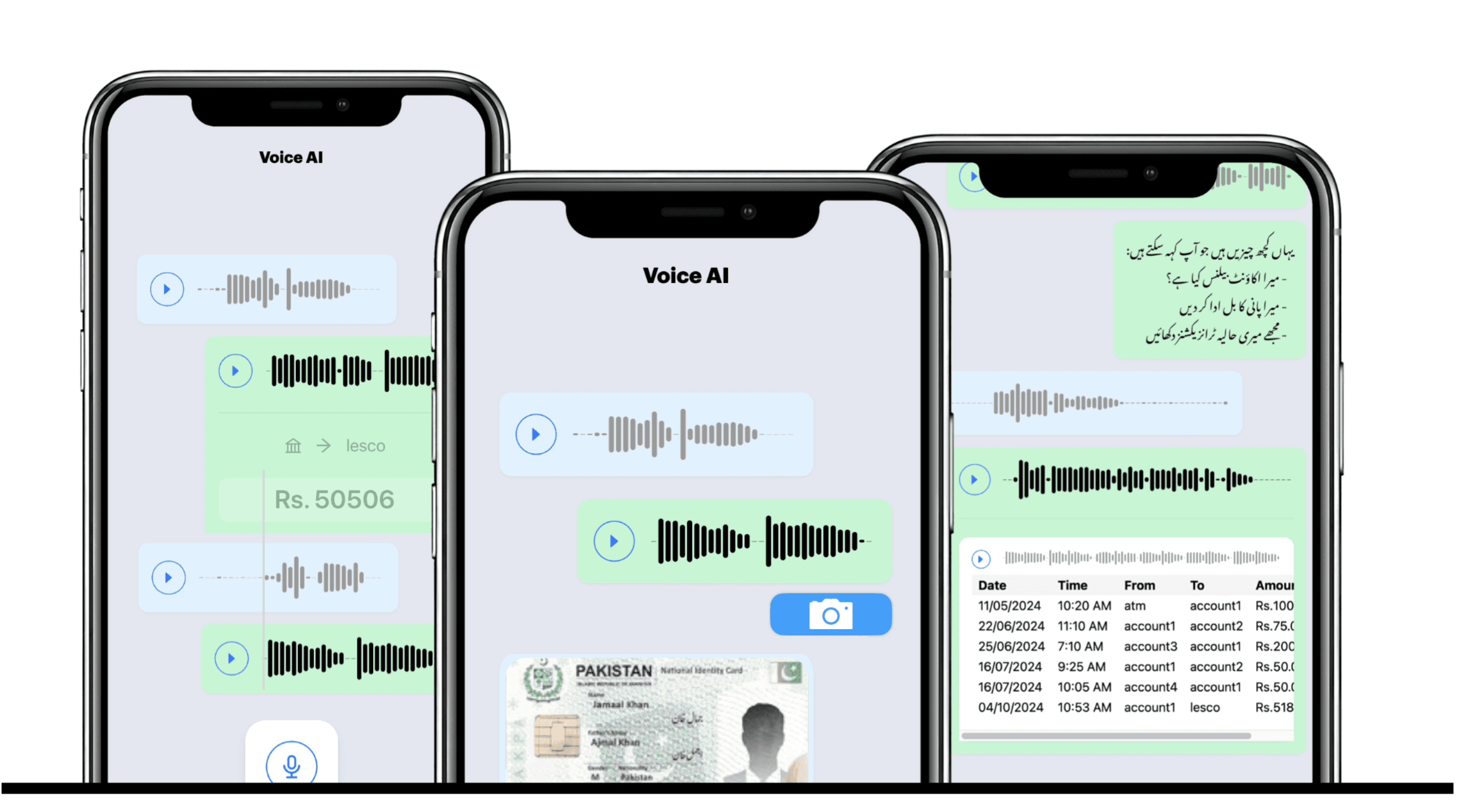
La collecte de données vocales et l'entraînement de modèles est le processus de collecte de données audio parlées et de leur utilisation pour entraîner des modèles d'intelligence artificielle et d'apprentissage automatique. Cela implique l'annotation, la segmentation et le prétraitement d'enregistrements vocaux pour créer un jeu de données d'entraînement robuste. Les modèles qui en résultent permettent une reconnaissance vocale précise, le traitement du langage naturel (TLN) et des interfaces utilisateur vocales personnalisées.
Le processus commence par la définition des besoins linguistiques, des accents, des domaines et du volume de données nécessaires au projet.
Les données vocales brutes sont collectées dans des conditions contrôlées et annotées par des linguistes pour la transcription, l'intention et les entités.
Les jeux de données annotés sont utilisés pour entraîner des modèles d'IA, ensuite validés sur leur précision et robustesse dans des scénarios réels.
Authentification vocale sécurisée et reconnaissance de la parole pour la banque téléphonique et la détection de fraude dans les conversations financières.
Développer des assistants vocaux pour la prise de notes patients et l'aide au diagnostic en analysant les plaintes et descriptions de symptômes.
Former des assistants virtuels à comprendre les requêtes clients et fournir des réponses naturelles et liées aux produits en temps réel.
Des systèmes contrôlés par la voix en atelier permettent des commandes sans contact et signalent les incidents via l'analyse audio.
Intégrer des commandes vocales naturelles dans les logiciels d'entreprise pour améliorer la productivité et l'accessibilité.
Bilarna évalue tous les fournisseurs de collecte de données vocales et d'entraînement de modèles à l'aide d'un Score de Confiance IA propriétaire de 57 points. Cela inclut une vérification rigoureuse de l'expertise technique en traitement audio, de la qualité du portfolio, des certifications de confidentialité comme ISO 27001 et des antécédents éprouvés de livraison. Bilarna surveille en continu les performances et les retours clients pour ne lister que des partenaires de haut niveau.
Les coûts varient considérablement selon l'étendue, la diversité linguistique et la complexité de l'annotation. Les projets vont de quelques milliers d'euros pour des jeux de données basiques à des sommes à six chiffres pour des modèles multilingues et sectoriels. Les prix sont souvent indiqués par heure audio annotée ou sous forme de forfait projet.
Un projet complet, de la collecte à la validation du modèle, prend généralement de 8 à 16 semaines. Le délai est influencé par le volume de données requis, la disponibilité des locuteurs et la profondeur de l'annotation linguistique. L'itération et l'affinage du modèle nécessitent des cycles supplémentaires.
Les modèles génériques sont pré-entraînés sur du langage général mais sont souvent peu performants dans des contextes spécialisés. Les modèles personnalisés sont entraînés avec des données et une terminologie spécifiques, offrant une précision bien supérieure sur le jargon, les accents et les termes techniques. Ceci est crucial pour les applications professionnelles.
Des modèles robustes nécessitent des centaines d'heures de parole transcrite de haute qualité, avec des locuteurs et accents divers. La qualité critique réside dans l'annotation précise des intentions, entités et émotions, pas seulement dans le volume. Les données doivent aussi être représentatives des scénarios réels de déploiement.
Évaluez les fournisseurs sur leur expertise linguistique, leur expérience dans votre secteur, leurs protocoles de confidentialité et sécurité, et la transparence de leur processus d'annotation. L'accès à un pool diversifié de locuteurs démographiquement pertinent et des preuves de performance sur des projets antérieurs sont essentiels.
Les données de sentiment sont mises à jour en quasi temps réel dans les outils d'analyse des médias sociaux. 1. Les données sont généralement actualisées toutes les quelques heures pour garantir des informations à jour. 2. Cette mise à jour fréquente permet aux utilisateurs de suivre efficacement les tendances émergentes. 3. Elle permet de répondre rapidement aux changements significatifs du sentiment public sur les plateformes sociales.
Les données des plugins et thèmes WordPress dans les outils de détection sont mises à jour régulièrement pour maintenir la précision. Pratiques générales de mise à jour : 1. Les outils de détection collectent continuellement de nouvelles données issues des analyses quotidiennes des utilisateurs et des sites web. 2. Les bases de signatures des plugins et thèmes sont fréquemment actualisées, souvent trimestriellement ou plus, pour inclure les nouvelles versions et mises à jour. 3. Les mises à jour intègrent les nouvelles versions de plugins, thèmes personnalisés et motifs émergents pour améliorer les taux de détection. 4. Les utilisateurs bénéficient d'une meilleure précision et reconnaissance des composants WordPress les plus récents à chaque cycle de mise à jour.
L'IA peut générer une liste qualifiée d'acheteurs ou de cibles M&A incluant l'analyse de données et les modèles de contact en moins de cinq minutes en suivant ces étapes : 1. Saisissez vos critères M&A dans la plateforme IA. 2. L'IA traite et analyse rapidement les données pertinentes du marché et des entreprises. 3. Elle produit une liste longue d'acheteurs ou cibles qualifiés. 4. Le système fournit des analyses de données prêtes à l'emploi et des modèles de contact pour une utilisation immédiate. Ce délai rapide accélère la recherche et la préparation du contact en M&A.
Les entreprises peuvent déployer et tester de nouveaux modèles de classement utilisant des technologies de recommandation et de recherche adaptatives en quelques jours plutôt qu'en plusieurs mois. Le processus rationalisé permet de passer des connexions de données à des expériences prêtes pour la production en moins d'une semaine, généralement environ sept jours. Cette rapidité d'expérimentation permet aux entreprises d'itérer rapidement, de tester plusieurs modèles et d'optimiser efficacement leurs algorithmes de recherche et de recommandation. En conséquence, les entreprises peuvent réagir plus rapidement aux changements du marché et aux retours des utilisateurs, en conservant un avantage concurrentiel et en améliorant continuellement l'expérience utilisateur et les résultats commerciaux.
Un plan d’action hebdomadaire peut être élaboré rapidement grâce aux insights des données retail, généralement en 20 minutes. Le processus comprend : 1. Collecte des données clients et ventes pertinentes. 2. Analyse des données pour identifier tendances et opportunités d’amélioration. 3. Utilisation d’un moteur de recommandation pour générer des insights exploitables. 4. Priorisation des actions selon leur impact potentiel et faisabilité. 5. Documentation claire du plan pour une exécution par les équipes en magasin durant la semaine.
Les cookies et les données sont utilisés à plusieurs fins avant de continuer sur un site web : 1. Fournir et maintenir les services du site. 2. Surveiller les interruptions et protéger contre le spam, la fraude et les abus. 3. Comprendre comment les services sont utilisés et améliorer la qualité du service en mesurant l'interaction des utilisateurs et les statistiques du site. 4. Si vous acceptez tout, les cookies sont également utilisés pour développer de nouveaux services, diffuser et mesurer l'efficacité des publicités, et afficher du contenu et des publicités personnalisés en fonction de vos paramètres et de votre activité. 5. Si vous refusez tout, les cookies sont limités aux fonctions essentielles sans contenu ou publicité personnalisés.
Connectez-vous à diverses sources de données pour créer des tableaux de bord complets. Suivez ces étapes : 1. Ouvrez votre outil de création de tableau de bord. 2. Sélectionnez l'option pour ajouter une source de données. 3. Choisissez parmi les sources prises en charge telles que MySQL, PostgreSQL, Google Sheets, Airtable et autres. 4. Entrez les identifiants ou clés API requis pour établir la connexion. 5. Vérifiez la connexion et commencez à utiliser les données dans votre tableau de bord.
Ces modèles d'avions sont principalement conçus pour servir l'industrie pétrolière et gazière ainsi que l'industrie militaire et de la défense. Leurs capacités, telles que les vols longue distance, les charges utiles et l'endurance, les rendent adaptés aux missions exigeantes dans ces secteurs. Les avions ont été testés dans des conditions difficiles et en eaux internationales, ce qui témoigne de leur robustesse et de leur fiabilité pour des opérations critiques. Leur conception et leur compatibilité avec les carburants JP-5 et Jet A-1 correspondent aux exigences opérationnelles typiques de ces industries, garantissant une performance efficace et efficiente des missions.
Connectez des bases de données relationnelles populaires à votre plateforme d'intelligence d'affaires IA. 1. Utilisez des identifiants sécurisés ou des chaînes de connexion pour lier des bases comme PostgreSQL, MySQL et SQLite. 2. Aucune migration ou duplication de données n'est nécessaire. 3. Le support pour d'autres bases comme Snowflake et BigQuery sera bientôt disponible.
Les outils internes peuvent se connecter à une grande variété de sources de données pour assurer une intégration fluide entre les systèmes d'entreprise. Ces sources incluent les bases de données traditionnelles, les API, les magasins vectoriels et les grands modèles de langage (LLM). En prenant en charge les connexions à n'importe quelle base de données ou API, les outils internes peuvent unifier l'accès aux données et les opérations, permettant aux entreprises d'optimiser les coûts et les performances en sélectionnant le meilleur modèle ou source de données pour chaque cas d'utilisation. Cette flexibilité permet aux organisations de créer des applications internes complètes qui fonctionnent avec leurs données, modèles et piles technologiques existants sans limitations.